
خزنده وب (Crawler)
یک کراولر (Crawler) یا خزنده وب (Web Crawler) نرمافزاری است که به صورت خودکار وبسایتها را پویش و اطلاعات مربوط به صفحات وب را جمعآوری میکند. کراولرها از طریق درخواستهای HTTP یا HTTPS به صفحات سایت دسترسی پیدا کرده و اطلاعات را استخراج میکنند. در این مقاله، به بررسی کراولرها، کارکرد آنها و کاربردهای آنها خواهیم پرداخت.
مفهوم و عملکرد خزنده وب
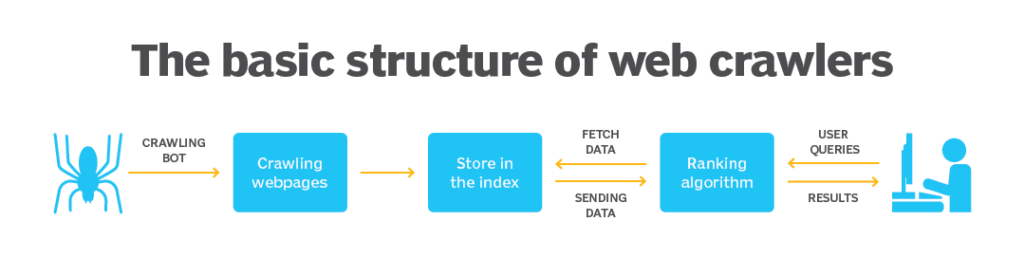
1. تعریف کراولر:
کراولر، همچنین به عنوان ربات وب یا جستجوگر وب شناخته میشود، یک نرمافزار است که به صورت خودکار وبسایتها را پویش کرده و اطلاعات مربوط به صفحات وب را جمعآوری میکند. کراولرها به طور مداوم از طریق درخواستهای HTTP یا HTTPS به صفحات وب دسترسی پیدا کرده و اطلاعات موجود در آنها را استخراج میکنند. این اطلاعات میتوانند شامل متن، تصاویر، لینکها، فایلها و سایر موارد مرتبط با صفحه باشند.
2. مراحل عملکرد کراولر:
عملکرد یک کراولر معمولاً شامل چند مرحله است که به ترتیب زیر هستند:
– شروع وبسایت اولیه: کراولر با شروع از یک وبسایت اولیه، معمولاً یک صفحه خاص، کار خود را آغاز میکند.
– تشخیص و دنبال کردن لینکها: کراولر به دنبال لینکهای موجود در صفحه فعلی میگردد و آنها را شناسایی میکند. سپس به این لینکها دنباله میدهد و به صفحات دیگری در وبسایت دسترسی مییابد.
– دریافت و پردازش محتوا: پس از دسترسی به هر صفحه، کراولر محتوای مربوطه را دریافت میکند. این شامل متن، تصاویر، فایلها و سایر موارد مرتبط با صفحه است. معمولاً کراولرها این اطلاعات را پردازش و استخراج میکنند تا بتوانند اطلاعات مورد نیاز را استخراج کنند.
– ذخیره اطلاعات: پس از پردازش محتوا، کراولر اطلاعات استخراج شده را ذخیره میکند. این میتواند در پایگاه داده محلی یا در سیستم فایلهای کراولر باشد. این اطلاعات به عنوان منبعی برای تحلیلهای بعدی، فرآیندهای جمعآوری داده و سایر کاربردها مورد استفاده قرار میگیرند.
3. روشهای پویش:
کراولرها از روشهای مختلفی برای پویش صفحات وب استفاده میکنند. در زیر، دو روش معمول استفاده شده توسط کراولرها را بررسی میکنیم:
– روش عمق اول (DFS): در این روش، کراولر از وبسایت اولیه شروع میکند و به عمق صفحات را پیمایش میکند. به عبارت دیگر، ابتدا تمام لینکهای موجود در صفحه اولیه را بررسی میکند، سپس به صفحه مربوط به هر لینک میرود و همین روند را تکرار میکند. این روش معمولاً به صورت عمقی عمل میکند و به صورت پیشفرض، یک کراولر فقط تا یک سطح عمق پیمایش میکند.
– روش سطح اول (BFS): در این روش، کراولر ابتدا لینکهای موجود در صفحه اولیه را بررسی میکند، سپس به صفحه مربوط به هر لینک میرود و لینکهای موجود در آن صفحه را بررسی میکند. به این ترتیب، کراولر ابتدا به تمام صفحات در یک سطح میرسد و سپس به سطح بعدی پیش میرود. این روش معمولاً به صورت افقی عمل میکند و تمام صفحات در یک سطح را پیمایش میکند، سپس به سطح بعدی میرود.
– روش مبتنی بر اولویت (Priority-based): در این روش، به هر صفحه یک اولویت یا امتیاز تخصیص داده میشود و کراولر ابتدا به صفحات با امتیاز بالا دسترسی مییابد. این امتیازها ممکن است بر اساس معیارهای مختلفی مانند اهمیت صفحه، ترافیک وبسایت، تعداد لینکها و سایر عوامل تعیین شود. با استفاده از این روش، کراولر میتواند به صورت هوشمندانهتری به صفحات دسترسی پیدا کند و به صفحاتی با اهمیت بیشتر تمرکز کند.
– روش مبتنی بر قوانین (Rule-based): در این روش، کراولر بر اساس قوانین و محدودیتهای خاصی عمل میکند. قوانین ممکن است شامل محدودیتهایی در مورد عمق پویش، نوع صفحات، روشن بودن فایل robots.txt و سایر موارد باشد. با استفاده از این روش، میتوان کنترل دقیقتری بر روی عملکرد کراولر داشت و محدودیتهای مورد نظر را در نظر گرفت.
بخش دوم: کاربردها و مزایای خزنده وب
کراولرها یا وبکراولرها در صنعت وب و در بسیاری از زمینهها استفاده میشوند. این ابزارها قادرند به طور خودکار و بدون نیاز به دخالت دستی، صفحات وب را پویش کنند و اطلاعات موجود در آنها را جمعآوری کنند. در زیر به برخی از کاربردهای اصلی کراولرها اشاره میکنم:
1. موتورهای جستجو:
کراولرها نقش بسیار مهمی در موتورهای جستجو مانند گوگل، بینگ و یاهو دارند. آنها صفحات وب را به صورت مداوم پویش کرده و اطلاعات موجود در آنها را به بانک اطلاعاتی خود اضافه میکنند. این اطلاعات سپس توسط الگوریتمهای جستجوی پیشرفته بررسی و تحلیل میشوند تا نتایج جستجو دقیقتر و مرتبطتری به کاربران ارائه شود.
2. جمعآوری داده:
کراولرها میتوانند برای جمعآوری دادهها از وبسایتها استفاده شوند. به عنوان مثال، شرکتها و سازمانها میتوانند کراولرها را برای جمعآوری اطلاعات بازاریابی، اخبار، نظرات کاربران و سایر دادههای مرتبط با کسب و کار خود استفاده کنند.
3. پایش وبسایت:
کراولرها میتوانند برای پایش وبسایتها و تشخیص تغییرات در آنها استفاده شوند. با پویش مکرر صفحات وب یک وبسایت، میتوان تغییرات مانند افزودن محتوا، حذف صفحات، تغییرات در ساختار وبسایت و غیره را تشخیص داد.
4. رتبهبندی و ارزیابی سایتها:
کراولرها میتوانند برای ارزیابی و رتبهبندی وبسایتها و صفحات وب استفاده شوند. با جمعآوری اطلاعات مرتبط با عوامل مختلف مانند کلمات کلیدی، لینکها، سرعت بارگیری و سایر معیارها، میتوان سایتها را مقایسه و رتبهبندی کرد.
5. نظارت بر پیشروی رقبا:
کراولرها میتوانند برای نظارت بر وبسایتها و فعالیتهای رقبا استفاده شوند. با کراول کردن صفحات وب رقبا، میتوان به تغییرات در محتوا، استراتژیهای بازاریابی، قیمتها و سایر عوامل مرتبط با رقبا دسترسی پیدا کرد و از آنها برای بهبود استراتژی خود استفاده کرد.
6. مانیتورینگ عملکرد وبسایت:
کراولرها میتوانند برای مانیتورینگ عملکرد و عملکرد وبسایتها مورد استفاده قرار گیرند. آنها میتوانند معیارهایی مانند زمان بارگیری صفحات، وضعیت کد پاسخ سرور، ارتباطات خراب، خطاهای برنامهنویسی و سایر موارد را بررسی کنند و به مدیران وبسایت اطلاعات لازم را برای بهبود عملکرد و رفع مشکلات ارائه دهند.
7. مطالعه و تحلیل دادههای وب:
کراولرها میتوانند برای جمعآوری دادههای وب و سپس تحلیل آنها به منظور استخراج اطلاعات مفید و الگوهای مختلف استفاده شوند. این اطلاعات میتوانند در تحلیل بازار، پژوهشهای علمی، پیشبینی روندها و سایر کاربردها مورد استفاده قرار گیرند.
بخش سوم: چالشها و مسائل مربوط به خزنده وب
1. محدودیتها و رفع مشکلات:
در این بخش، به قوانین و محدودیتهایی که برای استفاده از کراولرها وجود دارد، اشاره میکنیم. این شامل قوانین robots.txt، محدودیتهای IP، و مسائل حریم خصوصی است.
کراولرها ممکن است با محدودیتها و مشکلاتی در هنگام پویش صفحات وب مواجه شوند. به برخی از این محدودیتها عبارتند از:
1. فایل robots.txt: برخی وبسایتها فایلی به نام robots.txt در ریشه سایت خود قرار میدهند که قوانین و محدودیتهایی را برای کراولرها تعیین میکند. کراولرها باید این فایل را بررسی کنند و مطابق با قوانین در آن عمل کنند.
2. سرعت پویش: برخی وبسایتها ممکن است محدودیتهایی را برای سرعت پویش کراولرها تعیین کنند. این محدودیتها ممکن است شامل تعداد درخواستها در واحد زمان، زمان بین درخواستها و سایر موارد باشد. کراولرها باید این محدودیتها را رعایت کنند تا از مسدود شدن یا مشکلات دیگر جلوگیری کنند.
3. صفحات پویش نشده: برخی صفحات وب ممکن است به دلایلی از پویش کراولرها محروم شده و از طریق فایل robots.txt یا سایر مکانیزمها به آنها دسترسی ممنوع شود. در نتیجه، کراولرها نمیتوانند به اطلاعات موجود در این صفحات دسترسی پیدا کنند.
4. لینکهای تکراری و بیاثر: در هنگام پویش وب، ممکن است لینکهای تکراری یا بیاثری وجود داشته باشند که به تکرار و بیهودهتر شدن فرآیند پویش منجر میشوند. برخی کراولرها از روشها و الگوریتمهایی برای شناسایی و حذف لینکهای تکراری و بیاثر استفاده میکنند تا بهبودی در عملکرد کراولر ایجاد شود.
2. مسائل اخلاقی:
در این بخش، به برخی از مسائل اخلاقی مربوط به استفاده از کراولرها، مانند حفظ حریم خصوصی، رعایت قوانین و حقوق مالکیت فکری، پرداخته میشود .مسائل اخلاقی مرتبط با چالشها و مسائل مربوط به رباتهای کراولر (Crawler) میتواند شامل موارد زیر باشد:
1. حریم خصوصی: رباتهای کراولر عموماً اطلاعات را از وبسایتها جمعآوری میکنند. اگر این اطلاعات شامل اطلاعات شخصی کاربران باشد، میتواند به نقض حریم خصوصی و حقوق کاربران منتهی شود.
2. محتوای غیراخلاقی: در صورتی که رباتهای کراولر بدون تنظیمات مربوطه از سایتها اطلاعات جمعآوری کنند، ممکن است به محتوای غیراخلاقی یا غیرقانونی دسترسی پیدا کنند و این مسئله با مسائل اخلاقی مربوط به انتشار و دسترسی به محتوای نامناسب همراه باشد.
3. انصاف در دسترسی به منابع: رباتهای کراولر میتوانند منابع محدودی مانند پهنای باند و منابع سرور را در اختیار یک وبسایت قرار دهند. این میتواند به اشکال در عدالت در دسترسی به منابع و توزیع غیرمتعادل منابع منجر شود.
4. رعایت قوانین و محدودیتها: رباتهای کراولر باید قوانین و محدودیتهای مربوط به دسترسی به وبسایتها را رعایت کنند. این شامل قوانینی مانند robots.txt یا محدودیتهای مربوط به سرعت دسترسی به سایتها میشود. عدم رعایت این قوانین میتواند به نقض اخلاقی و قانونی منجر شود.
5. تأثیر بر عملکرد وبسایتها: رباتهای کراولر ممکن است به دلیل بار زیادی که بر روی وبسایتها ایجاد میکنند، تأثیر منفی بر عملکرد و عملکرد وبسایت داشته باشند. این میتواند به مسائل اخلاقی مربوط به تعدیل و دسترسی به منابع دیگران منجر شود.
در کل، مسائل اخلاقی در مورد رباتهای کراولر معمولاً در مرتبه استفاده مناسب از این رباتها، رعایت حریم خصوصی، انصاف در دسترسی به منابع و رعایت قوانین و محدودیتهای مربوطه تمرکز دارد. سازمانها و توسعهدهندگان رباتهای کراولر نیاز دارند تا مسائل اخلاقی مربوطه را در طراحی و استفاده از این رباتها مد نظر قرار داده و به آنها رسیدگی کنند.
نتیجهگیری:
خزنده وب به عنوان یک ابزار قدرتمند در جمعآوری و سازماندهی اطلاعات وب، نقش مهمی را ایفا میکند. با استفاده از خزندهها، میتوان به صورت خودکار و بدون نیاز به تداخل انسانی، صفحات وب را جستجو کرده و اطلاعات مورد نیاز را استخراج کرد.
دیدگاهتان را بنویسید